BABE Baseline — RoBERTa Fine-tune Reproduction
Reproduction of sentence-level media bias classification on the BABE dataset (Spinde et al., EMNLP Findings 2021), using RoBERTa-base.
Goal
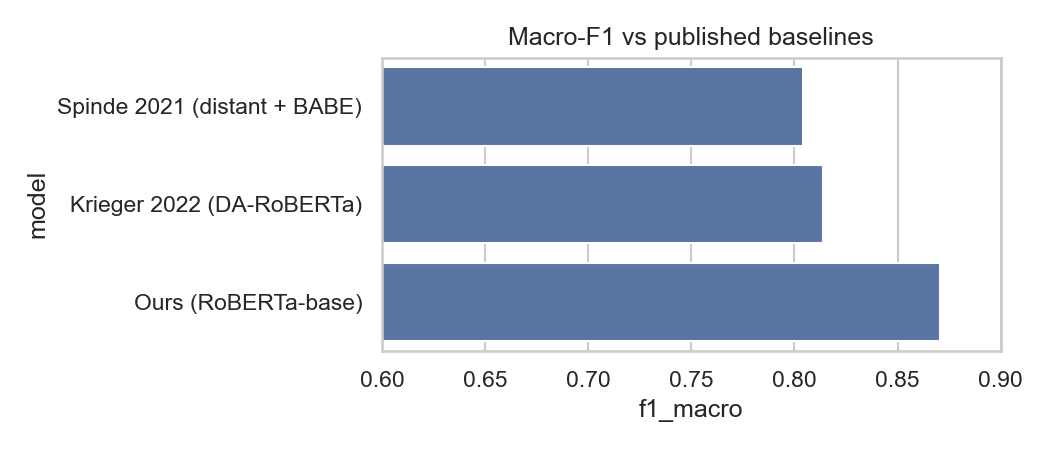
Reproduce the binary biased / non-biased sentence classifier from BABE and compare against published baselines:
- Spinde et al. 2021 (distant supervision pre-train + BABE fine-tune): F1 ≈ 0.80
- Krieger et al. 2022 (DA-RoBERTa, JCDL): F1 ≈ 0.81
Target: match or exceed published baselines with a clean RoBERTa-base fine-tune (no distant supervision, no DAPT).
Results
5-fold stratified cross-validation on BABE:
| Model | Macro-F1 |
|---|---|
| Spinde et al. 2021 (distant supervision + BABE) | 0.804 |
| Krieger et al. 2022 (DA-RoBERTa, DAPT, JCDL) | 0.814 |
| This repo (RoBERTa-base, 5-fold CV) | 0.857 ± 0.012 |
K-fold summary
| Metric | Mean ± Std |
|---|---|
| Macro-F1 | 0.857 ± 0.012 |
| Accuracy | 0.858 ± 0.012 |
| Precision (macro) | 0.856 ± 0.011 |
| Recall (macro) | 0.859 ± 0.012 |
| Biased F1 | 0.869 ± 0.011 |
Per-fold macro-F1: 0.876, 0.854, 0.845, 0.852, 0.856. Best fold is fold_0 with macro-F1 0.876, which is the checkpoint selected for Hugging Face release.
Held-out quick-run evaluation
On a held-out single-split test run (n=468), the model reaches 0.870 macro-F1.
| Pred non-biased | Pred biased | |
|---|---|---|
| True non-biased (207) | 180 | 27 |
| True biased (261) | 33 | 228 |
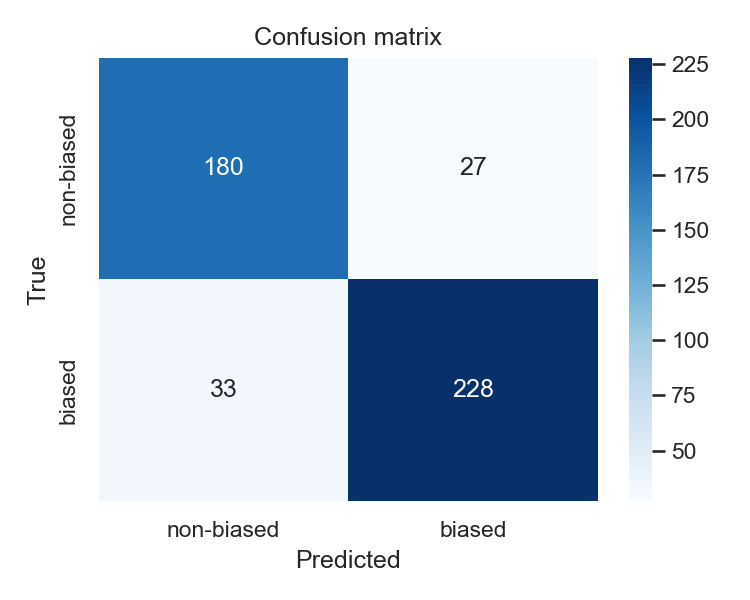
This quick-run split is slightly optimistic relative to the 5-fold mean, so the cross-validation number is the main result to report. See results/ for full metrics and error analysis.
Model access
- Training code and notebooks: vulonviing/babe-roberta-baseline
- Trained model weights and tokenizer: vulonviing/roberta-babe-baseline
- GitHub is for code, notebooks, documentation, and result artifacts in
results/. - Hugging Face Hub is for the released checkpoint (
fold_0) and model card. - Model weights are intentionally not stored in git.
- Release notebook:
notebooks/huggingface_upload.ipynb
What is excluded from git?
The repo keeps code and lightweight artifacts under version control, but excludes large or regenerable files:
models/for local checkpointsdata/raw/for downloaded source datadata/processed/for regenerated parquet splitswandb/for experiment logs.venv/and Python cache files
Download the released model from Hugging Face instead of GitHub:
from transformers import AutoModelForSequenceClassification, AutoTokenizer
repo_id = "vulonviing/roberta-babe-baseline"
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModelForSequenceClassification.from_pretrained(repo_id)Key findings
- A plain RoBERTa-base fine-tune is enough to reproduce the BABE task strongly: 5-fold CV reaches
0.857 ± 0.012macro-F1, above the published baselines listed above. - The quick held-out run reaches
0.870macro-F1, which is slightly optimistic relative to the CV mean but consistent with the same overall result. - Errors are concentrated in subtle framing and loaded-language cases rather than only overtly emotional or partisan wording.
For details, see:
notebooks/02_data_exploration.ipynbfor class balance, length statistics, and sample sentences.notebooks/04_evaluation.ipynbfor confusion matrix, misclassified examples, and error analysis.notebooks/05_final_report.ipynbfor the final comparison table, summary figures, and reporting-ready takeaways.
Model details
| Item | Value |
|---|---|
| Base model | roberta-base |
| Task | Sentence-level media bias classification |
| Labels | non-biased, biased |
| Dataset | mediabiasgroup/BABE |
| Released checkpoint | models/fold_0/checkpoint-532 |
| Hugging Face repo | vulonviing/roberta-babe-baseline |
| Max sequence length | 128 |
| Epochs | 4 |
| Learning rate | 2e-5 |
| Batch size | 16 train / 32 eval |
| Weight decay | 0.01 |
| Warmup ratio | 0.1 |
| Random seed | 42 |
Pipeline
The project is a pipeline of 5 notebooks, each calling functions from src/. Notebooks are thin orchestrators; logic lives in scripts.
| Notebook | Purpose |
|---|---|
01_data_preparation.ipynb | Download BABE from HuggingFace, clean, split, save processed parquet |
02_data_exploration.ipynb | Class balance, length distributions, vocab stats, sample sentences |
03_fine_tuning.ipynb | Tokenize, fine-tune RoBERTa-base with HF Trainer, log to W&B |
04_evaluation.ipynb | 5-fold CV scores, confusion matrix, error analysis |
05_final_report.ipynb | Final plots and comparison table vs published baselines |
Run notebooks in order. Each is idempotent — re-running won't break the next.
For model release, use notebooks/huggingface_upload.ipynb. It is intentionally separate from the numbered pipeline above and only prepares/uploads the final Hugging Face checkpoint.
Project structure
.
├── src/ # importable Python package
│ ├── config.py # paths, hyperparameters, constants
│ ├── data.py # dataset loading, splits, preprocessing
│ ├── model.py # model + tokenizer factory
│ ├── train.py # training loop wrapper
│ ├── evaluate.py # metrics, k-fold CV
│ └── viz.py # plotting helpers
├── notebooks/ # pipeline notebooks (01 → 05) + separate HF upload notebook
├── data/
│ ├── raw/ # untouched HF download
│ └── processed/ # cleaned parquet splits
├── models/ # saved checkpoints
├── results/ # metrics, plots, error analysis
├── requirements.txt
└── README.mdSetup
python -m venv .venv
source .venv/bin/activate
pip install -r requirements.txtIf you have a GPU, install the matching torch build first. CPU works but training will be slow — Colab / Kaggle recommended for 03_fine_tuning.ipynb.
Data
BABE is loaded from HuggingFace: mediabiasgroup/BABE. The dataset is publicly licensed for research use; see the dataset card on HF for details. No raw data is committed to git.
Reproducibility
- Fixed seeds (
src/config.SEED = 42) - Pinned dependency versions in
requirements.txt - Processed splits saved as parquet so notebooks 02–05 don't re-download
- Final model published to HuggingFace Hub:
vulonviing/roberta-babe-baseline(after run)